
في 18 نوفمبر 2025، تعرضت شبكة Cloudflare، المزود الشهير لخدمات توزيع المحتوى (CDN) والأمن، إلى انقطاع كبير تسبب في فشل نقل حركة المرور الأساسية عبر شبكتها، مما أدى إلى انقطاعات في عدد من المواقع والخدمات العالمية.
هذا الحدث أثار قلق في مجتمع الإنترنت، نظرًا لاعتماد عدد ضخم من الشركات والخدمات على بنية Cloudflare التحتية لتقديم المحتوى، حماية المواقع، والمصادقة. فيما يلي تحليل شامل لما حدث، كيف تعاملت الشركة مع الأزمة، وما هي دروسها الفنية المستقبلية.
ماذا حدث؟ – تسلسل الحادث
- بدأ الانقطاع حوالي 11:20 بتوقيت UTC، عندما بدأت أنظمة Cloudflare تعاني من فشل في تسليم حركة المرور الأساسية.
- المستخدمون بدأوا يرون صفحات أخطاء HTTP من نوع 500، وهي تدل عادةً على أخطاء داخلية في السيرفر.
- بعد تحقيق أولي، اعتقدت فرق Cloudflare أن الانقطاع قد يكون نتيجة هجوم DDoS واسع النطاق، لكن هذا التفسير لم يكن صحيح.
- في وقت لاحق، عادت حركة المرور تدريجياً إلى مسارها الطبيعي بحلول 14:30 UTC، مع استكمال الاستعادة الكاملة بحلول 17:06 UTC.
السبب الجذري (Root Cause)
وفقًا لتوضيح رسمي من Cloudflare في مدونة الشركة، فإن السبب لم يكن هجوم خارجي، بل خطأ داخلي مرتبط بإدارة التهديدات (Bot Management):
- قامت Cloudflare بتغيير صلاحيات أحد أنظمتها القاعدية (قاعدة بيانات ClickHouse) في سياق تحسين الأمان.
- هذا التغيير أدى إلى إنشاء إدخالات مكرّرة في ملف تكوين داخلي (feature file) يستخدمه نظام إدارة البوتات (Bot Management).
- نتيجة لذلك، تضاعف حجم هذا الملف بشكل غير متوقع، ما جعله يتجاوز الحدود المسموح بها من قبل برمجية التوجيه داخل شبكة Cloudflare.
- عند محاولة الأنظمة قراءة هذا الملف الضخم، فشلت بعض مكونات “البروكسي الأساسي” (proxy core)، مما تسبب في انهيار جزئي لأنظمة التوجيه.
- لحل المشكلة، قررت Cloudflare استرجاع نسخة قديمة من الملف (rollback) واستبداله بالإصدار السابق المعروف بأنه يعمل ضمن الحدود المقبولة.
- كما أوقفت الشركة مؤقتًا نشر النسخ الجديدة من الملف لحين ضمان أن تكون إضافات التكوين أكثر أمان وأصغر حجم.
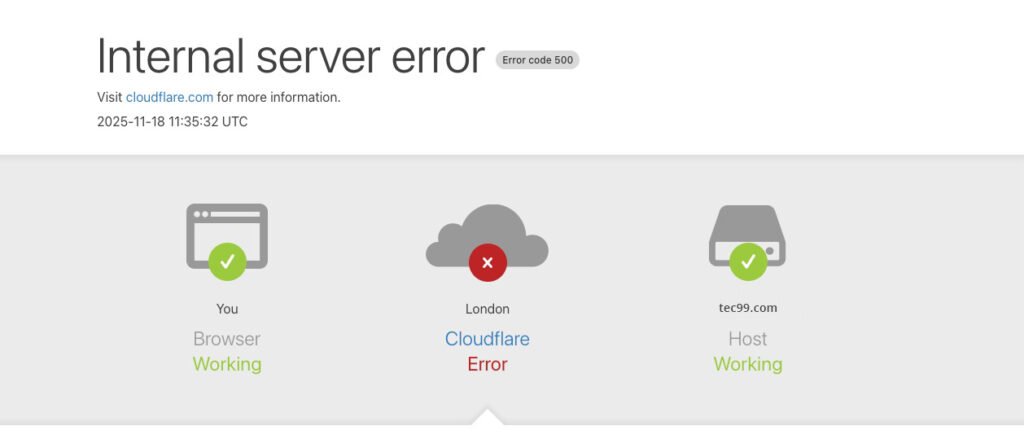
ما الخدمات التي تأثرت؟
خلال الحادث، تأثرت عدة منتجات وخدمات من Cloudflare بشكل ملحوظ:
| الخدمة | طبيعة التأثر |
|---|---|
| Core CDN و Security | طلبات الزوار تلقت أخطاء HTTP 500 بسبب فشل البروكسي. |
| Turnstile | فشلت آلية التحدي/التحقق (challenge) الخاصة بالمصادقة، مما منع تسجيل الدخول أو تنفيذ بعض العمليات على بعض المواقع. |
| Workers KV | ارتفعت معدلات الأخطاء HTTP 500 عند الوصول إلى KV (قاعدة البيانات الموزعة). |
| Dashboard | لوحة تحكم Cloudflare كانت تعمل جزئياً، لكن عدد كبير من المستخدمين لم يتمكن من تسجيل الدخول بسبب فشل Turnstile. |
| Access | فشلت محاولات المصادقة بشكل واسع وانتشرت أخطاء تسجيل الدخول. |
| Email Security | تعرضت لبعض التأثر في دقة التصفية (spam detection) بسبب فقدان مصدر تقييم السمعة مؤقتًا، رغم أن الخدمة الأساسية لم تتوقف. |
استجابة Cloudflare ومرحلة الاستعادة
بعد تحديد المشكلة، اتخذت Cloudflare عددًا من الإجراءات السريعة والفعالة:
- استرجاع نسخة أقدم: تم استبدال الملف المتضخم (feature file) بإصدار يعمل ضمن الحدود الآمنة.
- إيقاف التوزيع: أوقفت الشركة نشر النسخ الجديدة من هذا الملف إلى بقية الشبكة، حتى يتم إعادة تصميم التكوين بطريقة أكثر أمان.
- مراقبة شاملة: بعد استعادة التكوين، راقب فريق Cloudflare ازدحام حركة المرور بانتظام وتأكد من انخفاض معدلات الخطأ.
- خطوات مستقبلية للتعزيز: في مدونتها، أعلنت الشركة عن أنها ستعمل على:
- تعزيز آليات التحقق على التكوينات التي تنشئها أنظمتها، بحيث تكون محصنة تجاه الأخطاء أو الزيادات المفاجئة في الحجم.
- إضافة “مفاتيح قتل (kill switches)” عالمية لميزات محددة تتيح تعطيلها سريعًا إذا ظهرت سلوكيات غريبة.
- تحسين معالجة التقارير والأخطاء التي قد تستهلك موارد النظام (مثل التفريغ التلقائي للذاكرة أو تقارير الأعطال) حتى لا تثقل الأداء في أوقات الذروة.
- مراجعة هندسية: الشركة تعتزم مراجعة تصميم البروكسي الأساسي لتحديد حالات فشل إضافية محتملة وتعزيز المتانة ضدها.
الأثر والأهمية بالنسبة لعالم الإنترنت
هذا الحادث يسلط الضوء على بعض النقاط الحيوية:
- اعتماد عالمي كبير: عدد كبير من المواقع والخدمات تعتمد على Cloudflare لتوزيع المحتوى والأمان. أي انقطاع في بنيتها التحتية ينعكس بسرعة على الإنترنت العام.
- الشبكة الحية والمركبة: البنية التي تديرها Cloudflare ليست بسيطة؛ إنها تتضمن قواعد بيانات، ملفات تكوين، وحدات أمان مثل إدارة البوتات، وكل جزء من هذه البنية يمكن أن يمثل نقطة فشل إذا لم يصمم بعناية.
- إدارة مخاطر التكوين: التغيير الذي بدا في البداية تحسين أمني (صلاحيات قاعدة البيانات) تحول إلى خطأ جسيم بسبب تكوين غير محكم. هذا يؤكد أهمية اختبار التعديلات في بيئات معزولة قبل نشرها على نطاق واسع.
- شفافية الشركة: Cloudflare نشرت تقريرًا فنيًا مفصلاً (post-mortem) فسر ما حدث بدقة، وهو ما لاقى إشادة من مجتمع المطورين والمستخدمين.
- دروس للمستقبل: الإجراءات التي أعلنت عنها الشركة (kill switches، تحسين التكوين، مراجعة معمقة) مهمة جدًا لتقوية البنية التحتية ومنع تكرار مثل هذا الانقطاع.
توصيات لمشغلي المواقع والمطورين
على ضوء هذا الحادث، يمكن للمطورين ومديري المواقع اتخاذ بعض الخطوات الوقائية:
- خطة بديلة (Failover): تأكد من وجود آلية بديلة لتوزيع المحتوى أو حماية الموقع في حال فشل مزود CDN أو الأمان.
- مراقبة دقيقة: استخدم أدوات مراقبة الأخطاء وزمن الاستجابة (latency) لتكتشف مشاكل بسرعة.
- اختبار التكوينات: إذا كنت تستخدم ميزات متقدمة مثل Bot Management أو قواعد خاصة بالأمان، اختبر التعديلات في بيئة تجريبية قبل نشرها.
- التواصل مع مزودك: تابع حسابات الحالة (status) الخاصة بمزودي البنية التحتية مثل Cloudflare بانتظام، واشترك في إشعارات الحوادث.
- إعداد الاستجابة للأزمات: ضع خطة داخلية للاستجابة للحوادث (Incident Response Plan)، تشمل من يتولى الاتصال والطوارئ التقنية والنسخ الاحتياطي.
الخلاصة
انقطاع Cloudflare في 18 نوفمبر 2025 كان واحد من أكبر التحديات التي واجهتها الشركة منذ سنوات. السبب الأساسي لم يكن هجوم خارجي، بل خطأ تكويني داخلي تسبب في تضخم ملف مهم فشل النظام في التعامل معه. رغم ذلك، تعاملت Cloudflare بسرعة ومهنية: حدت من الأثر، عكست التكوين، وقدمت خطة تحسينات لزيادة متانة بنيتها التحتية.
بالنسبة لمجتمع الإنترنت، يمثل الحادث تذكير قوي بكيفية أن الأخطاء الداخلية حتى تلك التي تأتي من تحسين الأمان يمكن أن تؤثر على النظام بأكمله. لكنه أيضًا دليل على أهمية الشفافية والاستجابة السريعة من مزودي البنية التحتية، وعلى ضرورة أن يكون لدى مطوري المواقع خطط طوارئ قوية.