
أعلنت Google رسميًا عن Gemma 4 في 31 مارس 2026 بوصفه أذكى عائلة نماذج مفتوحة لديها حتى الآن، مع تركيز واضح على الاستدلال المتقدم والعمل الوكيلي (agentic workflows)، والأهم من ذلك أن النموذج يأتي بأوزان مفتوحة وتحت رخصة Apache 2.0، ما يجعله موجه ليس فقط للعرض التقني، بل للبناء الفعلي على أجهزتك ومشاريعك ومنتجاتك.
توضح Google أيضًا أن Gemma تجاوز 400 مليون عملية تنزيل عبر الأجيال السابقة، وهو رقم يشرح لماذا تحولت هذه السلسلة إلى ساحة سباق حقيقية بين عمالقة نماذج الذكاء الاصطناعي مفتوحة المصدر.
من زاوية السوق، يمكن قراءة توقيت Gemma 4 على أنه رد تنافسي مباشر على زخم Llama 4 من Meta، الذي ظهر في 2025 كنموذج مفتوح المصدر ومتعدد الوسائط مع دعم سياق طويل جدًا.
لكن من المهم هنا أن نفرق بين الاستنتاج التحليلي والنص الرسمي، جوجل لم تقل حرفيًا إن Gemma 4 أطلق للرد على Meta، لكنها جعلت من الواضح أن المعركة لم تعد على من لديه نموذج أكبر، بل على من يقدم ذكاء أعلى لكل باراميتر وعلى أي جهاز يمكن تشغيله محليًا.
لماذا يعد Gemma 4 نقطة تحول؟
الاختلاف الجوهري في Gemma 4 ليس أنه نسخة أحدث فقط، بل أنه ينقل تقنيات التفكير العميق من الفئة الكبيرة إلى الفئة المفتوحة القابلة للتشغيل المحلي، Google تصف العائلة الجديدة بأنها مبنية على نفس الأبحاث والتقنيات التي وراء Gemini 3، مع دعوى واضحة بأن الفئة الجديدة تقدم مستوى غير مسبوق من intelligence-per-parameter.
كما تشير صفحة النموذج إلى أن جميع الإصدارات تدعم thinking mode القابل للضبط، مع دعم أصلي للـ function calling، وstructured JSON، وnative system instructions، وهي عناصر مهمة جدًا لأي مطور يريد بناء AI agent حقيقي لا مجرد chatbot عادي.
والأقوى هنا أن Google لا تبيع Gemma 4 كمنتج سحابي فحسب، بل كمنصة يمكنها أن تعيش على الأجهزة الاستهلاكية. في الإعلان الرسمي تقول الشركة إن النماذج الكبيرة متاحة للـ workstations والسيرفرات، بينما النسخ الأصغر مصممة للتنفيذ المحلي على اللابتوبات والهواتف.
كما تعرض جوجل جداول أداء رسمية تبين أن Gemma 4 31B يصل إلى المركز الثالث بين النماذج المفتوحة على Arena.ai، وأن نسخة 26B A4B تأتي في المركز السادس، مع قفزات قوية في اختبارات البرمجة والاستدلال مقارنة بجيل Gemma 3.
ما هي معمارية Gemma 4؟
تأتي العائلة الجديدة بأربعة نماذج رسمية وهم:
- E2B
- E4B
- 26B A4B
- 31B Dense.
النسختان E2B وE4B مخصصتان أكثر للأجهزة الطرفية والموبايل، بينما 26B A4B و31B Dense موجهان للـ GPUs ومحطات العمل والسيرفرات.
هذا فرق مهم عن الكثير من النماذج المفتوحة التي تعلن عن قدرات كبيرة ثم تتعثر عند أول محاولة تشغيل محلي حقيقية.
على مستوى الوسائط، Gemma 4 ليس نموذج نص فقط، Google تقول إن العائلة تتعامل مع النصوص والصور والفيديو، مع دعم صوتي أصلي في E2B وE4B تحديدًا.
كما تدعم النماذج نافذة سياق تصل إلى 128K في الأحجام الصغيرة، و256K في الأحجام الأكبر، ما يعني أنك تستطيع تمرير ملفات كود ضخمة أو وثائق طويلة جدًا في طلب واحد بدل تقطيعها إلى أجزاء كثيرة.
الأهم أن النموذج يفهم المحتوى المتعدد الوسائط بمرونة، بما يشمل الصور ذات نسب أبعاد مختلفة والوثائق والـ OCR والرسوم البيانية، مع دعم لأكثر من 140 لغة.
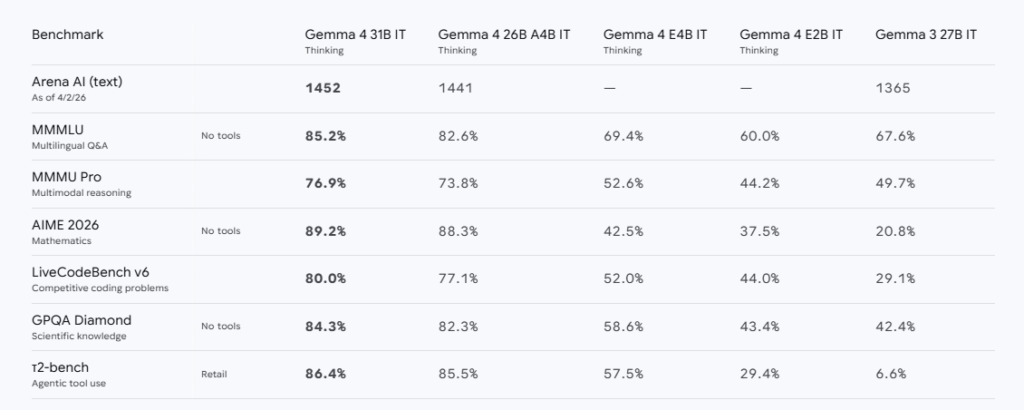
الفئات الرسمية في Gemma 4
Gemma 4 E2B: هذا هو الخيار الأخف والأقرب إلى التشغيل على الهواتف أو الأجهزة الضعيفة. وتذكر جوجل أنه مصمم للتنفيذ المحلي الفعال، مع سياق 128K، ودعم للنص والصورة والصوت. وفي سياق الـ Android، تصفه Google كخيار مناسب للسرعة القصوى والـ latency المنخفض.
Gemma 4 E4B: النسخة المتوازنة عمليًا، وهي الأهم للمطورين الذين يريدون ذكاء اصطناعي أعلى مع بقاء الهادوير في حدود معقولة. Google تنصح به في Android Studio كحل محلي، وتذكر أن الاحتياج الموصى به له هو 12 جيجابايت رام.
هذا يعني أن لابتوب بذاكرة 16 جيجابايت يستطيع أن يكون بيئة معقولة جدًا للفئة E4B، بينما الفئات الأكبر تحتاج تجهيز أقوى.
Gemma 4 26B A4B: هذه هي الفئة التي تبدو الجوكر الحقيقي للمطورين المحترفين، فهي لا تحمل 26B كوزن كامل فحسب، بل تستخدم بنية Mixture-of-Experts مع 3.8B active parameters فقط أثناء التنفيذ، ما يفسر لماذا تصفها Google بأنها قادرة على تقديم أداء قوي بسرعة أقرب إلى نموذج أصغر.
في Android Studio توصي Google بهذه الفئة للأجهزة عالية الأداء، مع 24 جيجابايت رام.
Gemma 4 31B Dense: هذا هو النموذج الأقوى في العائلة، والموجه للـ workstations والسيرفرات ومحطات الـ GPU الثقيلة. Google تشير إلى أنه يمكن أن يقدم أداء من الطراز الأعلى في فئته، وأنه يسجل نتائج قوية على اختبارات مثل Codeforces وAIME وGPQA، مع تصميم يجعله مناسب للأبحاث المتقدمة والبرمجة العلمية والمهام الوكيلية المعقدة.
هل يمكن تشغيله محليًا؟
نعم، وهذا هو جوهر الرسالة الجديدة، جوجل تقول إن النسخ الـ quantized من Gemma 4 يمكن أن تعمل محليًا على الـ GPUs، بينما تذكر أن النماذج الـ unquantized بصيغة bfloat16 تناسب GPU واحد من فئة 80GB NVIDIA H100.
وفي Android Studio، تذهب Google خطوة أبعد وهي أن النموذج المحلي لا يحتاج إلى اتصال إنترنت ولا API key لأعماله الأساسية، ما يضعه مباشرة في قلب فلسفة “local-first AI”.
أما على أندرويد، فالصورة أوضح من أي وقت مضى، Google أعلنت أن Gemma 4 صار متاح عبر Android Studio وAICore Developer Preview وML Kit GenAI Prompt API، وأنه أصبح الأساس للجيل الجديد من Gemini Nano 4 على الأجهزة، وتقول جوجل إن هذا الجيل الجديد أسرع حتى 4 مرات من النسخة السابقة ويستخدم حتى 60% بطارية أقل.
هذه أرقام تشرح لماذا تتعامل Google مع الذكاء الاصطناعي المحلي ليس كميزة جانبية، بل كمسار رئيسي للمستقبل.
Gemma 4 أم Llama 4: من الأسرع ومن الأذكى؟
هنا لا توجد إجابة واحدة تصلح لكل السيناريوهات.
من جهة ميتا، Llama 4 ظهر كعائلة open-weight natively multimodal مع context support ضخم، وتركز رسالته على المزج بين الوسائط المتعددة والسياق الطويل.
ومن جهة جوجل، Gemma 4 يتموضع كعائلة مفتوحة تركز بقوة على reasoning وcoding وagentic workflows وعلى تشغيل عملي محلي داخل بيئات المطورين وعلى Android.
لذلك فالمقارنة الأدق ليست من يفوز دائمًا؟، بل أي نموذج يخدم المهمة المطلوبة بأفضل توازن بين الذكاء الاصطناعي والهاردوير والخصوصية؟.
ولو أردنا تبسيط الصورة، فـ Llama 4 يبدو أكثر تمركز حول open multimodal scale، بينما Gemma 4 يبدو أكثر اهتمام بـ “local intelligence with real developer utility.
هذا استنتاج مبني على تحليلنا الشخصي، وليس حكم نهائي على كل benchmark، لأن التفوق الفعلي يتغير بحسب المهمة، واللغة، والسياق، والهاردوير، وطريقة التشغيل.
هل انتهى عصر الـ Cloud AI؟
لم ينتهي، لكنه بالتأكيد لم يعد الخيار الوحيد، Gemma 4 يثبت أن جزء كبير من قيمة الذكاء الاصطناعي يمكن أن ينتقل من مركز البيانات إلى الجهاز نفسه، سواء كان هاتف، لابتوب، أو محطة عمل. ومع ذلك، تظل Google نفسها تربط العائلة الجديدة بمنظومة أوسع تشمل النشر السحابي، والأبحاث، والضبط الدقيق.
أي أن المستقبل ليس “كلاود مقابل محلي”، بل كلاود + محلي + نماذج مفتوحة + تكامل عميق مع النظام.
الخلاصة
Gemma 4 ليس مجرد إصدار جديد، بل رسالة واضحة من Google مفادها أن الذكاء الاصطناعي المفتوح المصدر دخل مرحلة النضج.
النموذج صار أصغر عند الحاجة، وأقوى عند الضرورة، وأذكى في الاستدلال، وأقرب إلى المطور من أي وقت مضى.
وإذا كان Llama 4 قد رفع سقف المنافسة في multimodal open models، فإن Gemma 4 يضيف شئ آخر وهو إمكانية فعلية لتشغيل ذكاء اصطناعي قوي محليًا، داخل الأدوات والأجهزة التي يعمل بها المطورون كل يوم.