
في الأشهر الأخيرة، صار الحديث عن كفاءة تشغيل نماذج الذكاء الاصطناعي لا يقل أهمية عن الحديث عن حجمها وقدراتها.
وهنا يظهر TurboQuant كواحد من أكثر الأسماء لفتًا للانتباه، بعد أن كشفت Google Research رسميًا عن التقنية في 24 مارس 2026 بوصفها مجموعة خوارزميات quantization متقدمة ومؤسسة نظريًا، هدفها تحقيق ضغط كبير لنماذج اللغة الكبيرة (LLMs) ومحركات البحث.
ما هي TurboQuant؟
TurboQuant ليست مجرد تحسين تجميلي، بل مقاربة جديدة لضغط الأوزان وبيانات الذاكرة في نماذج الذكاء الاصطناعي. وفقاً لجوجل، التقنية مصممة لتحقيق massive compression مع الحفاظ على الدقة، وتستهدف بشكل خاص الـ key-value cache المستخدم في الاستدلال الطويل، إلى جانب تطبيقات vector search.
بصياغة بسيطة، TurboQuant تحاول حل المشكلة التي تتكرر في كل مرة نحاول فيها تشغيل نموذج ذكاء اصطناعي ضخم محليًا، النموذج قد يكون قوي، لكن الذاكرة ليست كذلك، وكلما تضخم السياق أو زاد طول المحادثة، تضخم معه عبء الـ KV cache، وهو ما يجعل الذاكرة لا المعالج وحده عنق الزجاجة الحقيقي في كثير من حالات التشغيل.
لماذا كانت هذه المشكلة معقدة أصلًا؟
في مرحلة الـ decode داخل الاستدلال، يصبح توليد كل token الجديد عملية مرتبطة بسرعة جلب الأوزان والـ KV cache من الذاكرة عالية النطاق الترددي إلى وحدات الحساب.
جوجل تصف هذه المرحلة بوضوح بأنها memory-bandwidth-bound، أي أن الأداء هنا يتحدد كثيرًا بسرعة الذاكرة، لا بالقوة الحسابية الخام فقط.
ولهذا السبب، يمكن أن تحقق تقنيات quantization تحسينات كبيرة جدًا، فخفض الأوزان من FP16 إلى INT8 أو INT4 يقلص حجم الذاكرة إلى النصف أو الربع.
تذكر Google Cloud أن 4-bit قد تقرأ حتى 4 مرات أسرع من 16-bit في هذا النمط من العمل.
كيف تعمل TurboQuant؟
تشرح Google Research أن TurboQuant تعتمد على مسارين رئيسيين وهما: PolarQuant وQJL.
تبدأ العملية بتدوير عشوائي للبيانات ثم ضغطها بطريقة عالية الجودة، بينما تأتي طبقة QJL لتقليل الانحياز وتحسين سلوك الاستدلال عند المستويات الأقل من الدقة.
الهدف النهائي هو ضغط شديد مع فقد شبه معدوم في الجودة.
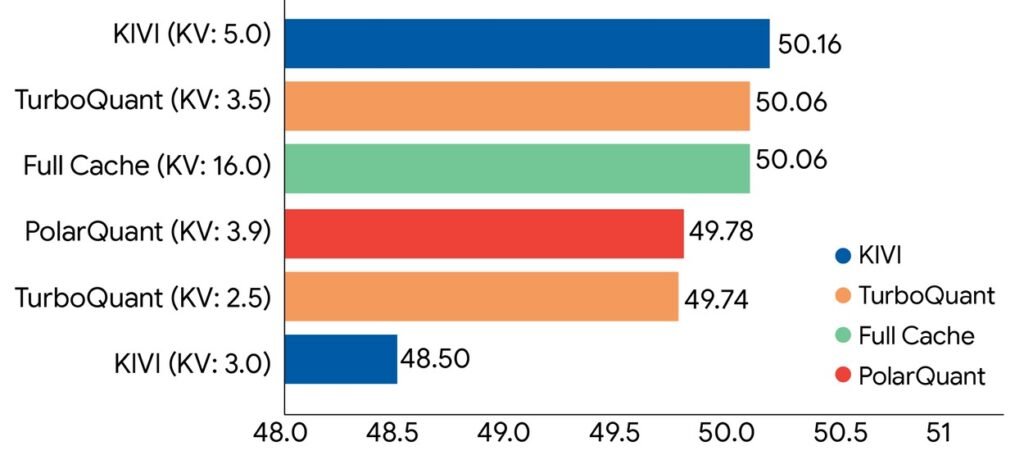
واللافت أن Google تقول إن TurboQuant تمكنت من ضغط الـ KV cache إلى 3 bits من دون الحاجة إلى training أو fine-tuning، ومن دون تضحية ملحوظة في دقة النموذج، مع overhead تشغيلي شبه معدوم.
هل فعلًا السرعة تصل إلى 4x؟
تذكر Google Cloud أن 4-bit يمكن أن تكون حتى 4x أسرع من 16-bit في مرحلة decode، لأن هذه المرحلة مقيدة بعرض النطاق الترددي للذاكرة.
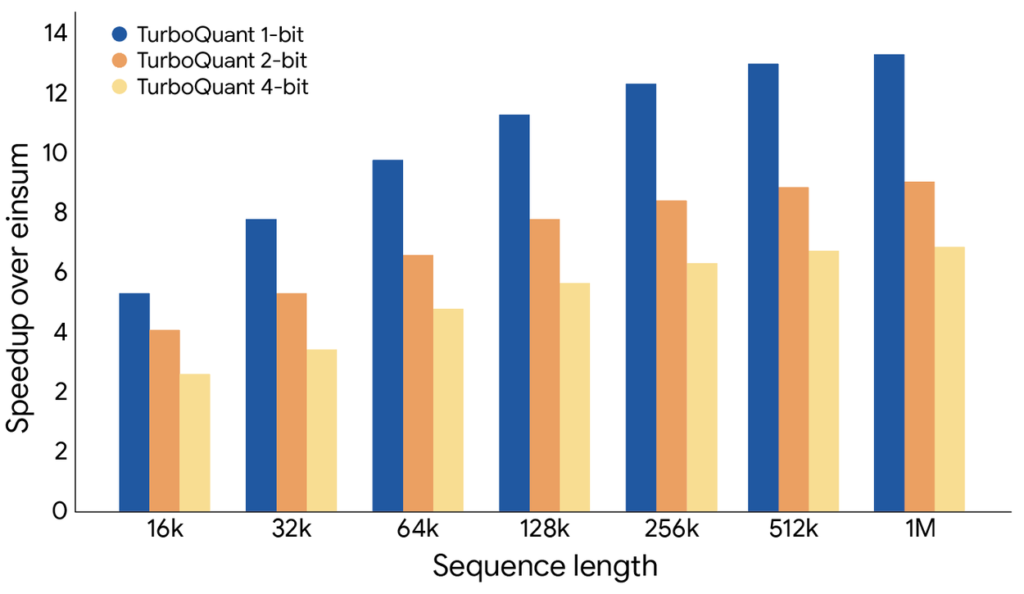
لكن Google Research تذهب أبعد من ذلك في أحد الاختبارات، حيث تشير إلى أن 4-bit TurboQuant حققت حتى 8x تحسن في حساب attention logits مقارنة بتوكن 32-bit غير المضغوطة على H100.
بمعنى آخر، رقم 4x ليس مبالغة إذا قرأته بوصف لبعض حالات الاستخدام، لكنه ليس رقم ثابت يصلح لكل نموذج وكل هاردوير وكل workload.
المكسب الحقيقي يتغير حسب نوع النموذج، وطول السياق، وطريقة القياس، ومكان الضغط الفعلي في السلسلة.
لماذا هذا مهم لمطوري الذكاء الاصطناعي؟
لأن TurboQuant لا تحاول فقط جعل النموذج أسرع، بل تجعل تشغيله أقرب إلى الواقع العملي.
عندما ينخفض حجم الـ KV cache بمعدل كبير، يصبح من الممكن خدمة سياقات أطول، وتقليل استهلاك الذاكرة، ورفع عدد الطلبات التي يمكن لسيرفر واحد التعامل معها قبل أن يصل إلى حد الضغط.
تعرض Google Research نتائج على LongBench وتذكر أن TurboQuant حققت في اختبارات تقليل في حجم ذاكرة key-value بما لا يقل عن 6x مع الحفاظ على النتائج النهائية عبر تلك الاختبارات.
هذا النوع من التحسينات يهم جدًا البيئات التي تعمل بنماذج طويلة السياق LLMs، أو محركات البحث، أو منصات الاستدلال التي تخدم عدد كبير من المستخدمين في الوقت نفسه.
كلما قلت تكلفة الذاكرة، صار تشغيل النموذج أقل كلفة وأكثر قابلية للتوسع.
ماذا يعني ذلك للمستخدم العادي؟
بالنسبة للمستخدم النهائي، الرسالة الأهم هي أن الذكاء الاصطناعي المحلي يقترب خطوة أخرى من الأجهزة الأقل قوة.
ليس معنى ذلك أن هاتف متوسط سيشغل أي نموذج ضخم بأقصى قدراته فورًا، لكن المعنى الأهم أن الفجوة بين “النموذج الـ AI الكبير” و”الجهاز المتواضع” بدأت تضيق، لأن التحسينات لم تعد تعتمد فقط على شراء GPU أكبر، بل على استغلال الذاكرة بذكاء أعلى.
وهذا الاستنتاج ينسجم مع تفسير Google Cloud بأن الـ decode غالبًا مقيد بسرعة الذاكرة، لا بالقوة الحسابية وحدها.
هل يعني ذلك أن كروت الشاشة الضخمة ستفقد أهميتها؟
ليس بهذه البساطة، فالمكسب الأكبر من TurboQuant وتقنيات شبيهة بها يأتي عندما يكون الضغط في الذاكرة، لا عندما يكون الحمل الحسابي هو المشكلة الأساسية.
لذلك، البطاقات ذات الذاكرة الأسرع وعرض النطاق الأعلى ستظل تستفيد أكثر في هذا النوع من السيناريوهات، لأن تحسينات quantization تتحول عمليًا إلى عمليات أكبر كلما كان الوصول إلى الذاكرة هو العامل الحاسم.
ماذا تعني TurboQuant لمستقبل الـ Edge AI؟
إذا استمرت هذه الفكرة في النضج، فسنرى مزيد من الذكاء الاصطناعي يعمل محليًا وعلى أطراف الشبكة، مع اعتماد أقل على الكلاود في بعض المهام.
جوجل لا تقول إن كل شيء سيصبح Edge AI غدًا، لكنها تعرض بوضوح أن خفض الذاكرة ورفع كفاءة الاستدلال هما الطريق الأقصر لجعل النماذج الضخمة (LLMs) أكثر قرب من الأجهزة اليومية.
أين تقف TurboQuant وسط اتجاهات جوجل الأخرى؟
المثير أن هذا الإعلان لا يأتي منفصل، بل ضمن سياق أوسع من تحسينات الاستدلال لدى جوجل.
قبل ذلك، ناقشت Google Cloud تقنيات مثل quantization وprefix caching وspeculative decoding وcontext-aware routing كأدوات عملية للوصول إلى “efficient frontier” في الاستدلال، وذكرت أن البنية الذكية وحدها قد تحقق مكاسب كبيرة جدًا في TTFT وcache efficiency حتى من دون تغيير الهاردوير.
هذا مهم لأن TurboQuant لا تبدو إذن كفكرة منفصلة، بل كقطعة في منظومة أكبر مثل: ضغط أذكى، ذاكرة أقل هدر، واستدلال أكثر توافق مع طبيعة الهاردوير في 2026.
الخلاصة: هل انتهى عصر الذاكرة الضخمة؟
الأرجح أنه لم ينتهي، لكنه تغير، لم يعد الفوز في الذكاء الاصطناعي متعلق بامتلاك أكبر ذاكرة فقط، بل بامتلاك أفضل طريقة لاستغلالها.
TurboQuant من Google Research تعطي لمحة واضحة عن مستقبل أقرب إلى “كفاءة أعلى” بدلًا من “ضخامة ذاكرة أكبر”، مع ضغط قوي للـ KV cache، وتحسينات عملية قد تصل في بعض الاختبارات إلى 8x، وتقليل معتبر في الحجم قد يتجاوز 6x في مهام long-context.
وبهذا المعنى، فإن السؤال الحقيقي لم يعد: “هل نحتاج كروت شاشة أكبر؟” بل: “كيف نجعل كل جيجابايت من الذاكرة تعمل بأقصى ذكاء ممكن؟” وهذا بالضبط هو الرهان الذي تدخل به TurboQuant إلى ساحة الذكاء الاصطناعي الحديثة.